
引用本文:
李琳, 钱四化, 吕天琦, 王宇辉, 郑建萍. 新一代测序技术的文库制备方法研究进展[J]. 应用化学,
2021, 38(1): 11-23.
doi:
10.19894/j.issn.1000-0518.200158

Citation: Lin LI, Si-Hua QIAN, Tian-Qi LYU, Yu-Hui WANG, Jian-Ping ZHENG. Recent Progress of Library Construction for Next-generation Sequencing[J]. Chinese Journal of Applied Chemistry, 2021, 38(1): 11-23. doi: 10.19894/j.issn.1000-0518.200158
Citation: Lin LI, Si-Hua QIAN, Tian-Qi LYU, Yu-Hui WANG, Jian-Ping ZHENG. Recent Progress of Library Construction for Next-generation Sequencing[J]. Chinese Journal of Applied Chemistry, 2021, 38(1): 11-23. doi: 10.19894/j.issn.1000-0518.200158
新一代测序技术的文库制备方法研究进展
English
Recent Progress of Library Construction for Next-generation Sequencing
Abstract:
High-throughput next-generation sequencing (NGS) is a revolutionary technology in gene sequencing. It is widely used in various solutions in biomedical-relevant fields. Library preparation with high quality and low-cost is the key for NGS. With the development of such sequencing platforms, different library preparation technologies have been built. However, these technologies also possess their own strengths and weaknesses. In this review, we first summarized various library preparation methods for NGS, then discussed the complete process of library preparation in single cell sequencing. We hope that this review can help researchers on the optimal selection of library preparation strategies and also offer suggestions for the development of new NGS library preparation technologies, especially in the exploitation of homebred kits.
-
Key words:
- Next-generation sequencing
- / Single cell sequencing
- / Library preparation
-
20世纪80年代,基于DNA测序技术,全球研究者通力合作启动“人类基因组计划”,测定了人类基因组DNA的30亿个碱基对的序列,成功绘制了人类基因组图谱[1-2]。这项工作为解码生命、了解生命起源、认识疾病发生机制和疾病治疗提供了科学依据。同时,“人类基因计划”的思想和技术也可用于研究其他生物,进而发展形成了基因组学。由此可见,基因测序技术是分子生物学最重要的研究工具之一,极大地推动了生物医学、药学和农学等相关领域的飞速发展。
目前,测序技术分为第一代测序技术和新一代测序技术,其中新一代测序技术包括以高通量闻名的第二代测序技术和具有超长读长优势的第三代测序技术[3]。测序前,实验对象中提取的核酸样品必须转换成标准样本,这种转换过程即为文库制备,转换后能直接用于测序的样品即为文库。文库的质量直接决定测序的准确性。因而,本文在已有研究的基础上,综述第二代测序和第三代测序文库制备方法,以及单细胞测序文库制备新方法。我们希望能够为研究人员在文库制备策略的选择以及新的文库制备技术尤其是国内起步较晚的文库制备试剂的开发提供指导。
1. 二代测序技术的文库制备方法
桑格测序技术[4]是测序的金标准,但是存在通量低、操作复杂和成本高等问题。为了克服桑格测序技术中存在的问题,基于焦磷酸测序、边合成边测序和连接法测序等原理,科学家们开发了高通量、低成本以及可自动化测序的二代测序技术[5]。二代测序技术可以在短时间内以较低单位成本实现数百万个DNA小片段的并行测序[6-9],是检测DNA和RNA序列的有力工具[10-12]。近年来,二代测序技术已经广泛应用于从头测序、靶向测序、单细胞测序、甲基化测序、免疫沉淀测序以及RNA免疫沉淀测序[13]。根据测序对象的不同,二代测序的文库制备方法分为基因组和转录组测序两类方法。
1.1 基因组测序的文库制备方法
基因组是生物体所有遗传物质的总和,具有一致性、稳定性和连续性,研究基因组对理解生命演变具有重要意义。基因组学研究分为结构基因组学和功能基因组学,二代测序技术是研究基因组结构的重要工具。因此,本文针对应用二代测序技术探究基因组结构的过程中所涉及的文库制备方法进行综述。根据样品打断方式的不同,基因组测序的文库制备方法可分为:物理性机械打碎和酶消化切割。
1.1.1 基于机械打碎的文库制备方法
机械打碎是使用物理的方法将DNA分子打碎成DNA小片段,包括超声波法、喷雾法和水动力剪切法[14]。基于超声波法研发的超声波破碎仪,是常用的DNA打碎设备。以PCR free文库试剂盒为例,如图 1所示,gDNA样品文库制备过程包括片段化、末端修复、脱氧腺苷(deoxyadenosine,dA)加尾以及连接接头步骤。
图 1
1.1.1.1 小片段DNA的末端修复及dA加尾
机械法打碎的DNA片段末端可能带有5′-凸出和3′-凸出,且其5′末端和3′末端不一定存在磷酸基团或羟基基团。为了将测序接头连接在DNA片段两端,必须将DNA的凸出末端转化成平末端且DNA的5′末端修饰磷酸基团,此过程即为末端修复。T4 DNA聚合酶或DNA聚合酶I(Klenow)大片段以及T4多聚核苷酸激酶的酶活性可以实现末端修复。在脱氧核糖核苷三磷酸(Deoxy-ribonucleoside Triphosphate,dNTP)存在的条件下,T4 DNA聚合酶或DNA聚合酶I大片段的DNA聚合酶活性将5′端突出末端补平。待dNTP耗尽,T4 DNA聚合酶或DNA聚合酶I大片段的3′-5′DNA外切酶活性又会将3′端突出末端切平。随后T4多聚核苷酸激酶的正向反应活性,在腺苷三磷酸(Adenosine Triphosphate,ATP)存在条件下,实现DNA的5′平末端磷酸化。
DNA末端修复后,基于Klenow片段的DNA聚合酶非模板依赖性DNA聚合酶活性且缺失3′-5′DNA外切核酸酶活性,DNA的3′端又选择性地添加并保存dA。然而,T4 DNA聚合酶或DNA聚合酶I大片段的3′-5′DNA外切核酸酶活性与Klenow片段的DNA聚合酶非模板依赖性DNA聚合酶活性不能兼容,因此DNA末端修复和DNA末端加dA必须分为两步进行,中间必须进行DNA纯化。Taq DNA聚合酶与Klenow片段具有相同的酶活性,但是Taq DNA聚合酶仅在高温72 ℃具有活性,而T4 DNA聚合酶和T4多聚核苷酸激酶仅在低温20 ℃具有活性,所以Taq DNA聚合酶不会干扰DNA修复过程。因此,Taq DNA聚合酶替代DNA聚合酶I大片段可以在同一试管中完成末端修复和dA加尾,简化文库制备流程,缩短文库制备时间[15]。
1.1.1.2 DNA片段连接接头
采用Illumina测序平台进行测序时,文库制备试剂的接头通常包括与固定在流动槽中寡核苷酸序列互补的序列(P5/P7)以及簇生成引物序列(Read SP)。为了充分利用测序空间,节约成本,通过在接头中插入用于标记不同文库的标签序列(index),对不同样本进行同时测序。建库试剂盒中常用的接头结构包括平端双链接头、U型接头和Y型双链接头,但这些接头连接效率较低。冯延叶等[16]将开放式的Y型接头一条链延长,且增加的序列与较短链上的序列反向互补,在长链不互补位置形成单个泡型接头。泡型结构的张力能确保接头解链,同时有效地减少接头二聚体(接头自连)。NEBNext DNA文库制备试剂采用包含尿嘧啶的发夹结构接头,发夹结构可以减少接头二聚体,从而提高接头与DNA片段末端的连接效率。
传统方法采用连接酶催化DNA片段与接头连接,此过程容易形成接头二聚体和片段二聚体(片段自连)。本课题组郑建萍研究员首次利用拓扑酶高效连接DNA的独特特点,创新性地开发出高效且高质量的DNA文库制备试剂“Topomize DNA Library Prep Kit”[17](如图 2)。该试剂利用DNA拓扑酶激活接头形成DNA拓扑接头(TOPO-adaptor),随后与末端修复的DNA片段直接连接,从而省略了DNA的5′端磷酸化以及dA加尾过程,可以处理10 ng到1μg的DNA样本,时间控制在90 min内。
图 2

1.1.2 基于酶消化切割的文库制备方法
酶消化法主要利用核酸外切酶或Tn5转座酶切割双链DNA。NEBNext DNA双链片段化酶包括两种酶,一种酶随机地在双链DNA上产生切刻,另一种酶识别切刻处并对DNA链进行切割,产生双链DNA片段,建库流程与机械打断法类似。Tn5转座酶可以在DNA链上随机插入部分序列。基于这一特性,Nextera XT DNA文库制备试剂利用Tn5转座酶在溶液中打断DNA链,并在其末端连接接头(如图 3)[18-19]。所得DNA片段通过PCR扩增反应嵌入index以及P5/P7,即可得到待上机测序片段,待其完成洗脱与混合后即可上机测序,具体建库流程见图 3(a)。Nextera DNA Flex文库制备试剂则采用固定有转座酶的磁珠,在磁珠上同时介导DNA片段化与接头序列标记DNA片段,具体建库流程见图 3(b)。本课题组郑建萍研究员带领团队自主研发的“MCNext DNA Sample Prep Kit”也是基于转座酶原理,采用两个不同的转座酶二聚体切割DNA,实现了有方向地打碎DNA。总而言之,采用转座酶的建库方法简化了文库制备步骤,能明显缩短建库时间。
图 3

当样品DNA长度超过测序仪测序范围时,可以采用物理性机械打碎及酶消化切割的方法进行DNA文库制备。而靶向测序仅对PCR扩增得到的特定区域序列进行测序,且扩增获得的DNA链长度通常不超过200 bp,因此不需要进行DNA片段化步骤。于个性化设计的多对引物,Ion AmpliSeq文库制备试剂盒可靶向扩增多个基因[20]。
1.2 转录组测序的文库制备方法
转录组是指特定细胞或组织中全部转录产物,包括信使RNA(Messenger RNA,mRNA)、核糖体RNA(Ribosomal RNA,rRNA)、转运RNA(Transfer,tRNA)及其它的非编码RNA(noncoding RNAs,nc RNA)。转录组学通过研究特定条件下基因编码RNA和非编码RNA的表达水平及其调控规律,进一步推动基因功能和nc RNA调控机制的研究。目前,广泛应用于生物体转录组分析的方法包括基于杂交的基因芯片和基于NGS的RNA测序(RNA sequencing,RNA-seq),其中RNA-seq是最主要的检测手段[21-23]。
与DNA-seq直接对DNA进行测序分析不同,RNA-seq将RNA反转录成cDNA后,通过对cDNA进行测序来间接获得转录组信息,以NEBNext Ultra II RNA文库试剂盒为例,如图 4所示,mRNA样品文库制备过程包括目标RNA靶向富集,RNA片段化,反转录生成第1条cDNA链,合成第2条cDNA链,末端修复,dA加尾,连接接头以及PCR扩增步骤。同时,RNA的大小、序列、结构和数量均存在差异,因此不同类型的RNA文库制备方法各不相同。总之,转录组测序文库制备中主要需要考虑:1)如何从总RNA中捕获感兴趣的RNA类型;2)如何将RNA反转录成适当大小的cDNA片段;3)如何把接头连接到cDNA末端。
图 4

1.2.1 目标RNA富集方法
RNA文库制备首先必须从RNA样品中捕获感兴趣的RNA类型,即RNA富集。RNA样品富集策略主要包括靶向捕获目标RNA和消除rRNA。
1.2.1.1 靶向捕获聚腺苷酸化RNA
真核生物中,聚腺苷酸化(Polyadenylation,Poly(A))RNA包括mRNA和长非编码RNA(>200 nt),仅占总RNA量的1%~5%[24]。研究人员根据聚胸腺嘧啶(oligo-dT)与Poly(A)杂交的特性,设计oligo-dT探针,实现了从总RNA中捕获到聚腺苷酸化RNA的目的。商业试剂通常利用oligo-dT修饰的磁珠或纤维素或者反转录过程中利用oligo-dT引物富集聚腺苷酸化RNA。
1.2.1.2 消除rRNA实现目标RNA富集
oligo-dT探针富集的方法通常不适用于原核生物mRNA(未聚腺苷酸化)、福尔马林固定或石蜡包埋的RNA样品。RNA中存在大量rRNA,约占RNA总量的82%[25]。因此,消除rRNA可以实现目标RNA样品的富集目的。消除rRNA的方法主要包括Ribo-Zero-seq法、RNA酶消化法以及根据rRNA特性开发的方法[26]。
Ribo-Zero-seq法采用生物素标记的探针捕获rRNA,随后链霉亲和素修饰的纳米磁珠吸附探针,即可分离出溶液中的rRNA。基于Ribo-Zero-seq法原理,Peter等[27]开发了一款软件,可用于设计捕获不同rRNA的探针序列。酶消化法利用单链DNA探针吸附rRNA,通过核糖核酸酶H(RNase H)和脱氧核糖核酸酶H(DNase I)分别降解rRNA和DNA探针。RNase H是一种核糖核酸内切酶,能够特异性水解杂交到DNA链上的RNA磷酸二酯键。DNase I是一种非特异性核酸内切酶,切割DNA产生具有3′羟基和5′磷酸末端的二核苷酸、三核苷酸和寡核苷酸产物。
除了上述方法,还可以根据rRNA特性来消除rRNA。基于DNA复性动力学原理,C0T杂交法利用双链特异性核酸酶(Duplex-specific Nuclease,DSN)降解杂交过程中形成的双链cDNA[28]。高丰度RNA如rRNA形成双链cDNA的速度较快,所以降解得越多,而低丰度RNA如mRNA形成双链cDNA的速度较差,反而降解得越少。终止子核酸外切酶(5′-Monophosphate Dependent Terminator Exonuclease,TEX)法也可以实现选择性降解,TEX可降解带有5′单磷酸的RNA如rRNA和tRNA,而不会降解具有5′三磷酸、5′帽子结构(如大多数真核生物mRNA)或5′羟基的RNA[29]。
1.2.2 RNA/cDNA片段化方法
富集的核酸样品经打碎后符合测序仪要求的长度,该过程即RNA片段化。RNA片段化的方法包括化学法和酶消化法。化学法采用碱性溶液或二价正电离子如Mg2+溶液打断RNA。反应温度升高可以减小碱性溶液或二价正电离子对RNA结构的影响,但化学法的缺点是对RNA打断具有一定选择性,并不是随机性的片段化。酶消化法利用核糖核酸酶打断RNA,但这种酶倾向于打断双链RNA[30]。此外,还可以将RNA反转录成cDNA,运用DNA片段化方法如超声波法和转座酶等打碎cDNA。
1.2.3 RNA逆转录成cDNA方法
逆转录聚合酶链式反应(Reverse Transcription-Polymerase Chain Reaction,RT-PCR)是RNA逆转录的主要手段。RT-PCR反应过程中,随机引物或Oligo-dT反转录引物在反转录酶的作用下以mRNA片段为模板合成互补的cDNA[20, 31]。此外,特异性反转录引物也能将目标RNA反转录成cDNA,并且能抑制rRNA反转录。NuGEN Ovation RNA-seq采用DNA/RNA复合反转录引物,其DNA部分能特异性杂交5′端的ploy(A)[32]。
RNA逆转录合成第1条cDNA链后,以cDNA为模板在DNA聚合酶作用下可扩增生成第2条cDNA链。但此方法无法确认cDNA双链中哪一条链与初始RNA链一致,导致原始RNA链的信息丢失。例如,一些反义RNA可能具有调节基因表达的作用[33]。定向建库的策略是通过一定手段识别第二条cDNA链[34]。NEBNext Ultra Directional RNA Library Preparation Kit for Illumina在第2条cDNA合成过程中使用dUTP替代了dTTP,通过USER酶特异性识别并消化含有尿嘧啶的链,从而抑制第2条cDNA链的合成[35]。基于SMARTScribe反转录酶的末端转移酶活性,SMARTer Ultra Low RNA Kit for Illumina在第1条cDNA链3′端添加一段非模板序列作为标记,从而区分第二条cDNA链[36]。
1.2.4 cDNA/RNA片段连接接头
接头连接主要分为cDNA末端连接接头和RNA末端直接连接接头。cDNA末端连接接头方法与DNA建库方法一致。大部分商业化RNA-seq建库试剂盒如NEBNext Ultra RNA Library Prep Kit for Illumina和TruSeq RNA Sample Preparaticon均采用该策略完成建库。
小RNA长度为20~35 nt,且一般5′端有磷酸基团和3′端有羟基基团,因此小RNA不需要特殊修饰即可与接头连接[37]。TruSeq Small RNA Lirary preparation Kit和NEBNext Small RNA Library Prep Kit利用T4 RNA连接酶2[38](截短型)催化5′端预腺苷酸化的DNA接头与小RNA的3′端连接,且DNA接头的3′端封闭,可以减少产生接头二聚体。溶液中添加5′端RNA接头、ATP以及T4 RNA连接酶后,T4 RNA连接酶可催化接头与小RNA的5′端连接。
2. 三代测序技术的文库制备方法
过去十多年中,二代测序技术凭借其低成本、高通量的优势成为了主流测序技术。然而,二代测序读长短不利于生物信息学分析,且易受GC含量和重复读长的影响。为了更好地挖掘DNA/RNA信息,研究人员开发了超长读长且无需模板扩增的三代测序技术——单分子测序技术[39-40]。单分子测序技术主要包括单分子实时(Single molecule real-time,SMRT)测序技术[41]和单分子纳米孔(Nanopore)测序技术[42]。
2.1 SMRT测序的文库制备方法
SMRT测序的核心技术之一是零级波导技术(Zero Mode Waveguide, ZMW)[43]。ZMW是一个直径只有10~50 nm的孔,远小于检测激光的波长(数百纳米)。当激光打在ZMW底部时,激光无法穿过,而在ZMW底部发生衍射,只能照亮DNA聚合酶工作的区域。SMRT测序技术原理是ZMW底部捕获并固定与待测序模板结合的聚合酶,4种不同荧光标记的dNTP通过布朗运动进入检测区域与聚合酶结合,通过检测与模板配对碱基的荧光信号测定模板序列。
SMRT测序的文库制备主要是将发夹接头连接到片段化的DNA双链两端,形成闭合的环状单链模板,称之为SMRTbell[44]。较长的DNA片段,如Covaris和Hydroshear仪器打碎产生的DNA片段,经过末端修复可以直接连接钝化接头。而较短DNA片段,如PCR扩增得到的DNA片段,容易形成二聚体。为了减少DNA片段二聚体,DNA片段末端修复后增加了dA加尾步骤,同时发夹接头的5′端有一个能与DNA3′端互补配对的悬空的dTTP。发夹接头均包括DNA聚合酶的结合位点,因此SMRTbell的两端可以随机启动测序,且测完一条链后可以循环测其互补链。若聚合酶的活性足够长,则两条链可以进行多次测序。SMRT测序文库的DNA片段范围较广,最长文库片段超过20k bp。
SMRT测序文库制备无需将DNA打断成小片段,可以实现高GC含量区域片段的建库。同时,SMRT测序建库过程中无需模板扩增步骤,从而避免PCR所引入的错误,但这也导致文库质量直接决定测序结果。机械打碎引起的DNA损伤(DNA破裂或链内交联)或污染(单链DNA、RNA、蛋白质或残留荧光分子)均会影响测序结果。
2.2 Nanopore测序的文库制备方法
Nanopore测序技术的原理是蛋白纳米孔(微型小孔,本质上是在膜上形成通道)嵌入合成膜,并浸没在离子溶液中,使离子电流通过纳米孔[45]。当DNA或RNA链通过纳米孔时,会对电流产生干扰,引起电流信号的改变,且不同的碱基会引起不同的电流信号变化。因此,与基于光信号的测序技术不同,Nanopore测序技术通过解码核酸通过蛋白纳米孔时的电流信号来确定碱基序列。目前,测序长度可以达到150 kb,最长DNA测序长度达到2.3 Mb,直接RNA测序读长最长为26 kb。
Nanopore文库长度可达kb量级,且无需进行PCR扩增,因此文库制备过程比较简单。Nanopore测序的DNA文库制备方法与二代测序中基因测序文库制备方法类似,但与其他新一代测序文库的寡核苷酸接头不同,Nanopore文库的接头上还结合了马达蛋白。马达蛋白与膜上镶嵌的纳米孔蛋白结合后会解开DNA螺旋,并控制DNA/RNA链通过纳米孔的速度[46]。同时,Nanopore测序技术可以直接对RNA进行测序分析。因此,mRNA建库可以利用引物捕获mRNA,随后直接在mRNA末端连接Nanopore接头。mRNA建库还可以采用二代测序mRNA的建库方法,即进行逆转录反应并扩增成cDNA双链,再连接Nanopore接头。小RNA而言,可以采用高3′磷酸化短RNA序列的环化扩增及识别建库法(Circular Amplification and Identification of short RNA Sequences bearing a 3 Phosphate,CircAID-p-seq)进行建库。CircAID-p-seq将连接R(Linker R)链连接至RNA链3′末端并环化后,进行逆转录反应,从而生成多聚体cDNA双链。随后,按照DNA建库方式在多聚体cDNA双链连接接头,即可得到最终测序文库。
Nanopore的文库制备时间短,且文库长度范围比SMRT文库长度范围更广。但目前DNA链穿孔的速率过快,超过了现有光学和电子技术的检测分辨率,影响了单个核苷酸检测的灵敏度和准确性。因此,如何控制DNA链穿孔速率是Nanopore建库的关键。
3. 单细胞测序的文库制备方法
单细胞测序技术从单细胞水平分析基因组或转录组,可全面还原出细胞特征及群体间的差异,能更精确地解析细胞群体的异质性[47-50]。同时,针对某些稀有样品,单细胞测序技术也具有明显的应用优势。单细胞测序文库构建主要包括单细胞捕获、细胞裂解、DNA/cDNA预扩增以及文库构建等步骤。理论而言,预扩增后的DNA/cDNA经建库后可进行二代测序或三代测序,但目前大多数研究均采用二代测序平台进行测序。因此,预扩增后的DNA/cDNA可以选择不同二代测序建库策略进行建库。单细胞测序文库制备技术的发展主要集中在单细胞分离和预扩增的方法上,因而本文将针对单细胞分离和预扩增方法进行综述。
3.1 单细胞的分离方法
单细胞分离方法主要包括极限稀释法、显微操作法、荧光激活流式细胞分选法(flow-activated cell sorting, FACS)、激光捕获显微切割法(laser capture microdissection, LCM)、CellSearch、Mag-Sweeper、CellCelector以及Nanofilters(细胞筛)、微流控技术等9种方法[51]。微流控技术作为操纵微量液体的新兴技术,适用于将样品分离成单个细胞的处理操作[52]。因此,本文将集中介绍基于微流控技术的单细胞分离方法。
2013年,Fluidigm C1[53]结合微流控技术设计的整合微流体通路包含96个细胞捕获位点和多步反应隔室结构,可自动化完成96个细胞捕获、裂解与预扩增等过程。2015年,哈佛医学院的研究人员将微流控技术与纳升级液滴和条形码微珠结合,推出了Dropseq技术[54]和inDrop技术[55]。微流控技术将细胞、裂解液、逆转录试剂以及条形码微珠压缩在油包水液滴中,从而构成成千上万个独一无二的微滴反应体系。2017年,Zheng等[56]提出10×GemCode技术,该技术的核心是利用微流控技术,形成成千上万个油滴包裹的凝胶珠(Gel Bead in Emulsions,GEM),如图 5所示。合格的GME中包含一个凝胶珠、单个细胞以及裂解液、逆转录试剂。每个凝胶珠表面包被数百万条寡聚核糖核苷酸,其中14 bp序列用于标识GEM中捕获的细胞。目前,10×Genomics公司开发了多款试剂盒可用于单细胞基因组和转录组文库制备。其中,Next GEM Single Cell 5'Reagent Kits v2不仅有条形码标识单细胞,还通过特异性条形码(Feature Barcode)标识细胞表面蛋白,从而获得单细胞的免疫信息[57]。
图 5

10×GemCode技术可以实现自动化捕获高通量单细胞,但需要购置专门仪器。同时,微液滴中未捕获单细胞的GMEs和捕获双细胞的GMEs,会占用下游测序数据空间,增大下游测序成本。2018年,浙江大学郭国骥团队报道的Microwell-seq[58]结合微流控芯片和条形码磁珠捕获细胞。Microwell-seq以微孔阵列硅晶片为模板,灌入琼脂糖溶液形成自制凝胶微孔阵列,使每个微孔仅包含单个细胞和一个条形码磁珠。同时,自制凝胶微孔阵列可根据细胞的大小调整凝胶微孔阵列中微孔尺寸,且硅晶片可重复利用,从而降低单细胞捕获成本。
3.2 单细胞DNA/cDNA的预扩增
单个细胞中DNA/RNA含量极其稀少,因此获得单细胞后,如何对DNA或RNA逆转录形成的cDNA进行高效率、低偏倚性的预扩增是单细胞文库构建流程中的关键[59]。目前扩增的方法主要分为全基因组扩增(Whole-Genome Amplification,WGA)和全转录组扩增(Whole-Transcriptome Amplification, WTA)两大类。
多重置换扩增法(Multiple Displacement Amplification,MDA)[60]利用具有卓越的链置换、连续合成以及高保真特性的phi29 DNA聚合酶来完成扩增反应。等温条件下,随机引物与模板退火,扩增时phi29 DNA聚合酶取代模板的互补链,被取代的单链DNA作为新的模板进一步扩增。尽管MDA覆盖度高、准确性好、扩增子长,但存在等位基因缺失率高、指数扩增造成依赖于序列的偏差,以及忽略细胞间异质性等不足,不适合检测拷贝数变异。乳化液全基因组扩增(emulsion Whole-Ge-Nome Amplification, eWGA)[61]和微流控反应器单链测序(Single-Stranded Sequencing Using Microfluidic Reactors, SISSOR)[62]将待扩增DNA片段和扩增反应溶液分散至皮升级体系中,每个体系的最终饱和度一致,可以提高扩增均一性和准确度。拟线性扩增技术——多次退火环状循环扩增法(multiple annealing and looping-based amplification cycles,MALBAC)[63],在延伸形成半扩增子后升温使产物从模板脱落,降温形成发夹结构以防止进一步扩增,从而保证只基于原始模板上的扩增。基于Tn5转座酶随机打断和插入序列原理,转座酶插入的线性扩增法(Linear Amplofication via Transposon Insertion, LIANTI)利用LIANTI转座酶打断并插入T7启动子,进而通过体外转录以及反转录和第二条链合成,从而实现DNA线性扩增[64]。然而,DNA直接转移单细胞文库制备(direct DNA transposition single cell library preparation,DLP)方法跳过全基因扩增过程,而直接对单个细胞进行建库处理,从而避免了全基因组扩增所引入的误差[65]。
WTA需要将RNA逆转录成cDNA,然后采用cDNA扩增方法来进行扩增。cDNA扩增的方法包括末端加尾PCR扩增、体外扩增、半随机引物扩增以及模板切换法。其中Smart-seq[66]和Smart-seq2[67]所采用的模板切换法是最常用的cDNA扩增方法。模板切换法是反转录到达mRNA的5′末端时,反转录酶在cDNA的3′端加上数个胞嘧啶,以一段5′端含锚定序列且3′含有鸟嘌呤的寡核苷酸与cDNA的3′端胞嘧啶互补,随后反转录酶切换模板,以cDNA为模板进行扩增。然而,Ziegenhain等人比较6种常用的单细胞RNAseq方法,发现采用分子标签(unique molecular identifier,UMI)标记mRNA的方法,如图 5所示,可以降低扩增偏差[68]。因此,大多数WTA均在逆转录过程中在mRNA随机连上一个UMI。
4. 结论与展望
与传统的测序技术相比,NGS技术无疑是测序技术领域的一场革命。近年来伴随着各大测序平台的百花齐放,NGS的文库制备技术已经能够为各个生物科学领域,从基础研究到临床应用研究提供更为全面的解决方案。
二代测序的DNA文库制备主要分为机械打碎法和酶消化法策略,RNA文库制备策略比DNA文库制备策略更复杂,涉及目标RNA富集,RNA逆转录及不同类型RNA接头连接的方法。与二代测序建库相比,三代测序建库流程更加简捷。本文结合三代测序平台的原理,分别综述了SMRT建库和Nanopore建库的方法。目前,针对不同测序平台已经研发多种建库试剂,表 1对常用的第二代建库试剂和第三代建库试剂进行总结。另外,本文还综述了近年来飞速发展的单细胞测序的文库制备过程中涉及的各种单细胞分离方法和DNA/cDNA预扩增方法。
表 1
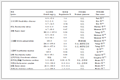 表 1 NGS文库制备试剂盒比较Table 1. Detailed comparison of the current NGS library preparation kits
表 1 NGS文库制备试剂盒比较Table 1. Detailed comparison of the current NGS library preparation kits 下载:
导出CSV
下载:
导出CSV
文库制备试剂盒
Library preparation kit输入量
Input插入片段长度
Insert size处理时间
Assay time扩增
Amplification公司/货号
Company/No第二代测序
The SecondTruSeq DNA PCR-Free 1 μg 350 bp or 550 bp 5 h No Illumina
20041794Generation Sequencing TruSeq DNA Nano 100 ng 350 bp or 550 bp 6 h Yes Illumina
20015964NEBNext Ultra II FS 500 pg~1 μg 50 bp~1000 bp 3.2 h Yes New England
Biolabs #E6177Topomize DNA 500 ng 500 bp 1.5 h Yes MCLAB
TOPO-100NexteraXT DNA 1 ng~500 ng 350 bp or 550 bp 3.5 h Yes Illumina
FC-131-1024Ion AmpliSeq 10 ng 100 bp~200 bp 3.5 h Yes Thermofisher
4480441NEBNext Ultra II
RNA10 ng~1 μg 200 bp
~ 500 bp6.8 h Yes New England
Biolabs #7770TruSeq RNA 0.1 μg~1 μg 200 bp~500 bp 10.5 h Yes Illumina
RS-122-2001第三代测序
The ThirdLigation 1 μg 150 kb 1 h No Nanopore
SQK-LSK109Generation Sequencing Rapid 400 ng 150 kb 10 min No Nanopore
SQK-RBK004PCR 100 ng PCR length PCR+1 h Yes Nanopore
SQK-PSK004Direct RNA 500 ng RNA length 1.7 h No Nanopore
SQK-RNA002PCR-cDNA 1 ng ploy(A) cDNA length 2.8 h Yes Nanopore
SQK-PCS109CircAID-p-seq 4.5 pg 20 bp~50 bp 24 h No Immagina Biotech
#CA001然而,文库制备技术依然面临着许多挑战,很多技术有待革新和发展。二代测序中冗长的文库制备步骤导致其不能广泛应用于重大疾病检测及急性疾病检测,同时基于扩增的文库制备技术还不能有效去除PCR所引入的错误。北京泛生子公司开发了一种快速构建扩增子文库的方法[69],根据目标扩增子设计上游融合引物和下游融合引物作为PCR反应体系中的引物组合,可实现一步法构建扩增子文库。Sequencing HEteRo RNA-DNA-hYbrid (SHERRY)在合成第一条cDNA链后,基于Tn5转座酶与RNA/cDNA异源双链核酸分子随机结合特性,直接插入测序接头,此方法不需要合成第二条cDNA链[70]。三代测序技术的文库制备简捷,建库时间短,文库长度长,但如何减少DNA损伤以及更好的纯化文库和如何通过控制DNA链穿孔的速率分别是SMRT和Nanopore测序建库的关键。单细胞测序现阶段已经实现自动化捕获单细胞,并进行DNA/cDNA预扩增,但此过程增加了建库成本。SPLiT-seq借鉴Drop-seq拆分重组的方法,直接在细胞体内完成逆转录和预扩增[71]。此方法既无需设计每个细胞单独的条码序列, 也无需将单细胞分隔至独立的反应体系中, 使用常规离心管或孔板即可完成文库制备前处理,降低了建库成本。总之,未来如何让NGS测序技术实现更快捷、更准确和更低廉地检测,是文库制备技术改进的方向。
-
-
[1]
刘威. 人类基因组计划大事件[J]. 生物化学与生物物理进展, 2001,28,(002): 135-136. LIU W. Human genome project[J]. Adv Biochem Biophys, 2001, 28(002): 135-136.
-
[2]
SHAHEENUZZAMN M D, LIU T X, SHI S D. Development of sequencing technology and role of next generation sequencing technology in wheat research: a review[J]. Pak J Bot, 2020, 52(5): 1867-1878.
-
[3]
SANGER F. Sequences, sequences, and sequences[J]. Annu Rev Biochem, 1988, 57(1): 1-28. doi: 10.1146/annurev.bi.57.070188.000245
-
[4]
METZKER M L. Applications of next-generation sequencing technologies-the next generation[J]. Nat Rev Genet, 2010, 11(1): 31-46. doi: 10.1038/nrg2626
-
[5]
LAISSUE P, VAIMAN D. Exploring the molecular aetiology of preeclampsia by massive parallel sequencing of DNA[J]. Curr Hypertens Rep, 2020, 22(4): 1-10. doi: 10.1007/s11906-020-01039-z
-
[6]
GOODWIN S, MCPHERSON J D, MCCOMBIE W R. Coming of age: ten years of next-generation sequencing technologies[J]. Nat Rew Genet, 2016, 17(6): 333-351.
-
[7]
NGUYEN H T, TRAN D H, NGO Q D. Evaluation of a liquid biopsy protocol using ultra-deep massive parallel sequencing for detecting and quantifying circulation tumor DNA in colorectal cancer patients[J]. Cancer Invest, 2020, 38(2): 85-93. doi: 10.1080/07357907.2020.1713350
-
[8]
ZHANG H Y, LIU R J, YAN C. Advantage of next-generation sequencing in dynamic monitoring of circulating tumor DNA over droplet digital PCR in cetuximab treated colorectal cancer patients[J]. Trasl Oncol, 2019, 12(3): 426-431. doi: 10.1016/j.tranon.2018.11.015
-
[9]
陈竺, 黄薇, 傅刚. 人类基因组计划现状与展望[J]. 自然杂志, 2000,22,(3): 125-133. doi: 10.3969/j.issn.0253-9608.2000.03.001CHEN Z, HUANG W, FU G. Current situation and prospects of the human genome project[J]. Chinese J Nat, 2000, 22(3): 125-133. doi: 10.3969/j.issn.0253-9608.2000.03.001
-
[10]
STARK R, GRZELAK M, GENETICS J. RNA sequencing: the teenage years[J]. Nat Rew Genet, 2019, 20(11): 631-656. doi: 10.1038/s41576-019-0150-2
-
[11]
QIN D H. Next-generation sequencing and its clinical application[J]. Cancer Biol Med, 2019, 16(1): 4-10.
-
[12]
TRAPNELL C, ROBERTS A, GOFF L. Differential gene and transcript expression analysis of RNA-seq experiments with tophat and cufflinks[J]. Nat Protoc, 2012, 7(3): 562-578. doi: 10.1038/nprot.2012.016
-
[13]
田李, 张颖, 赵云峰. 新一代测序技术的发展和应用[J]. 生物技术通报, 2015,31,(11): 1-8. TIAN L, ZHANG Y, ZHAO Y F. Development and application of new generation sequencing technology[J]. Biotech Bull, 2015, 31(11): 1-8.
-
[14]
KNIERIM E, LUCKE B, SCHWARZ J M. Systematic comparison of three methods for fragmentation of long-range PCR products for next generation sequencing[J]. Plos Ones, 2011, 6(11): 1-6.
-
[15]
孙子奎, 王峰, 丁方美, 等. 一种采用一步法进行DNA末端修复/加dA的方法及应用: 中国, 201610040334. O[P]. 2016-05-11.SUN Z K, WANG F, DING F M, et al. A one-step approach and application to DNA terminal repair/additon of dA: CN, 201610040334.O[P]. 2016-05-11.
-
[16]
冯延叶, 柴智, 张会, 等. 稳定性增加的测序文库接头: 中国, 111139533. A[P]. 2020-05-12.FENG Y Y, CHAI Z, ZHANG H, et al. Increased stability of the sequencing library adaptor: CN 111139533.A[P]. 2020-05-12.
-
[17]
ZHENG J, SHI C, SHEN D. Compositions and methods for preparing sequencing libraries: US, 20160349152.[P]. 2016-12-01.
-
[18]
MARINE R, POLSON S W, RAVEL J. Evaluation of a transposase protocol for rapid generation of shotgun high-throughput sequencing libraries from nanogram quantities of DNA[J]. Appl Environ Microbiol, 2011, 77(22): 8071-8079. doi: 10.1128/AEM.05610-11
-
[19]
KIA A, GLOECKNER C, OSOTHPRAROP T. Improved genome sequencing using an engineered transposase[J]. BMC Biotechnol, 2017, 17(6): 1-10.
-
[20]
JOUALI F, MARCHOUDI N, ANSARI F Z. SARS-CoV-2 genome sequence from Morocco, obtained using ion AmpliSeq technology[J]. Microbiol Resour Announ, 2020, 9(31): 1-3.
-
[21]
崔凯, 吴伟伟, 刁其玉. 转录组测序技术的研究和应用进展[J]. 生物技术通报, 2019,35,(7): 1-9. CUI K, WU W W, DIAO Q Y. Application and research progress on transcriptomics[J]. Biotech Bull, 2019, 35(7): 1-9.
-
[22]
HAN Y X, GAO S G, MUEGGE K. Advanced applications of RNA sequencing and challenges[J]. Bioinf Biol Insights, 2015, 9(S1): 29-46.
-
[23]
PISANO M P, TABONE O, BODINIER M. RNA-seq transcriptome analysis reveals LTR-retrotransposons modulation in human perpheral blood monouclear cells(PBMCs) after in vivo lipopolysaccharides(LPS) injection[J]. J Virol, 2020, 94(19): 1-25.
-
[24]
HRDLICKOVA R, TOLOUE M, TIAN B. RNA-seq methods for transcriptome analysis[J]. WIRES RNA, 2017, 8(1): 1-24.
-
[25]
HERBERT Z T, KERSHNER J P, BUTTY V L. Cross-site comparison of ribosomal depletion kits for illumina RNAseq library construction[J]. BMC Genomics, 2018, 19(199): 1-10.
-
[26]
BUSH S J, MCCULLOCH M E B, SUMMERS K M. Integration of quantitated expression estimates from polyA-selected and rRNA-depleted RNA-seq libraries[J]. BMC Bioinf, 2017, 18(18): 301-315.
-
[27]
CULVINER P H, GUEGLER C K, LAUB M T. A Simple, Cost-effective, and robust method for rRNA depletion in RNA-sequencing studies[J]. mBio, 2020, 11(2): 10-20.
-
[28]
ZHULIDOW P A, BOGDANOVA E A, SHCHEGLOV A S. Simple cDNA normalization using kamchatka crab duplex-specific nuclease[J]. Nucl Acids Res, 2004, 32(3): 1-8.
-
[29]
SHRMA C M, HAFFMANN S, DARFEUILLE F. The primary transcriptome of the major human pathogen helicobacter pylori[J]. Nature, 2010, 464(11): 250-255.
-
[30]
DRUSIN S I, RASIA R M, ORENO D M. Study of the role of Mg2+ in dsRNA processing mechanism by bacterial RNAse III through QM/MM simulations[J]. J Biol Inorg Chem, 2020, 25(1): 89-98. doi: 10.1007/s00775-019-01741-7
-
[31]
HEAD S R, KOMORI H K, LAMERE S A. Library construction for next-generation sequencing: overviews and challenges[J]. Biotechniques, 2014, 56(2): 61-64.
-
[32]
KURN N, CHEN P C, HEATH J D. Novel isothermal, linear nucleic acid amplification systems for highly multiplexed applications[J]. Clin Chem, 2005, 51(10): 1973-1981. doi: 10.1373/clinchem.2005.053694
-
[33]
SARANTOPOULOU D, TANG S Y, RICCIOTTI E. Comparative evaluation of RNA-Seq library preparation methods for strand-specifcity and low input[J]. Sci Rep, 2019, 9(7091): 1-10.
-
[34]
LEVIN J Z, YASSOUR M, ADICONIS X A. Comprehensive comparative analysis of strand-specific RNA sequencing methods[J]. Nat Meth, 2010, 7(9): 709-715. doi: 10.1038/nmeth.1491
-
[35]
PARKHOMCHUK D, BORODINA T, AMSTISLAVSKIY V. Transcriptome analysis by strand-specific sequencing of complementary DNA[J]. Nucl Acids Res, 2009, 37(18): 1-10.
-
[36]
MAGNOLIA B, NATHALIE B, ALISA L. Strand-specific transcriptome sequencing using SMART technology[J]. Curr Protoc Mol Biol, 2016, 116(1): 1-18.
-
[37]
HAFNER M, LANDFRAF P, LUDWIG J. Identification of microRNAs and other small regulatory RNAs using cDNA library sequencing[J]. Methods, 2008, 44(1): 3-12. doi: 10.1016/j.ymeth.2007.09.009
-
[38]
VIOLLET S, FUCHS R T, MUNAFO D B. T4 RNA ligase 2 truncated active site mutants: improved tools for RNA analysis[J]. BMC Biotech, 2011, 11(72): 1-14.
-
[39]
马丽娜, 杨进波, 丁逸菲. 三代测序技术及其应用研究进展[J]. 中国畜牧兽医, 2019,46,(8): 2245-2256. MAN L N, YANG J B, DING Y F. Research progress on three generation sequencing technology and its application[J]. China Anim Husb Vet Med, 2019, 46(8): 2245-2256.
-
[40]
许亚昆, 马越, 胡小茜. 基于三代测序技术的微生物组学研究进展[J]. 生物多样性, 2019,27,(5): 534-542. XU Y K, MA Y, HU X X. Analysis of prospective microbiology research using third-generation sequencing technology[J]. Biodivers Sci, 2019, 27(5): 534-542.
-
[41]
ARDUI S, ADAM A, VERMEESCH J R. Single molecule real-time(SMRT) sequencing comes of age: application and utilities for medical diagnostics[J]. Nucl Acids Res, 2018, 46(5): 2159-2168. doi: 10.1093/nar/gky066
-
[42]
JAIN M, OLSEN H E, PATEN B. The oxford nanopore minion: delivery of nanopore sequencing to the genomics community[J]. Genome Biol, 2016, 17(239): 1-12.
-
[43]
LEVENE M J, KORLACH J, TURNER S W. Zero-mode waveguides for single-molecule analysis at high concentrations[J]. Science, 2003, 299(5607): 682-686. doi: 10.1126/science.1079700
-
[44]
TRAVERS K J, CHINE C S, RANK D R. A flexible and efficient template format for circular consensus sequencing and SNP detection[J]. Nucl Acids Res, 2010, 38(15): 1-8.
-
[45]
WANG S Y, ZHAO Z Y, HAQUE F Z. Engineering of protein nanopores for sequencing, chemical or protein sensing and disease diagnosis[J]. Curr Opin Biotechnol, 2018, 51: 80-89. doi: 10.1016/j.copbio.2017.11.006
-
[46]
耿佳, 郭培宣. 噬菌体phi29 DNA包装马达磷脂嵌合体在单分子检测及纳米医学领域的应用[J]. 生命科学, 2011,23,(11): 1114-1129. GENG J, GUO P X. Membrane-embedded channel of bacteriophage phi29 DNA-packaging motor for single molecule sensing and nanomedicine[J]. Chin Bull Life Sci, 2011, 23(11): 1114-1129.
-
[47]
文路, 汤富酬. 单细胞转录组分析研究进展[J]. 生命科学, 2014,26,(3): 228-233. WEN L, TANG F C. Recent progresses in single-cell transcriptome analysis[J]. Chinese Bull Life Sci, 2014, 26(3): 228-233.
-
[48]
赵丽娜, 赵晓航. 循环肿瘤细胞单细胞测序-液体活检的新视角[J]. 生命科学, 2018,30,(1): 63-72. ZHAO L N, ZHAO X H. Single cell sequencing analysis of circulating tumor cells: a new horizon of liquid biopsy[J]. Chinese Bull Life Sci, 2018, 30(1): 63-72.
-
[49]
ZHENG C H, ZHENG L T, YOO J. Landscape of infiltrating T Cells in liver cancer revealed by single-cell sequencing[J]. Cell, 2017, 169(7): 1342-1356. doi: 10.1016/j.cell.2017.05.035
-
[50]
GUO X Y, ZHANG Y Y, ZHENG L T. Global characterization of T Cell in non-small-cell lung cancer by single-cell sequencing[J]. Nat Med, 2018, 24(7): 978-985. doi: 10.1038/s41591-018-0045-3
-
[51]
李贱成, 徐克前. 单细胞转录组测序技术及应用[J]. 生命的化学, 2020,40,(8): 1208-1219. LI J C, XU K Q. Single cell RNA sequencing technology and its applications[J]. Chem Life, 2020, 40(8): 1208-1219.
-
[52]
吴春卉, 姜有为, 程鑫. 微流控芯片在单细胞捕获中的应用[J]. 科技先导, 2018,36,(16): 39-45. WU C H, WANG Y W, CHENG X. Application of microfluidic chip in single cell capture[J]. Sci Tech Leader, 2018, 36(16): 39-45.
-
[53]
WU A R, NEFF N F, KALISKY T. Quantitative assessment of single-cell RNA-sequencing methods[J]. Nat Meth, 2014, 11(1): 41-46. doi: 10.1038/nmeth.2694
-
[54]
MACOSKO E Z, BASU A, SATIJA R. Highly parallel genome-wide expression profiling of individual cells using nanoliter droplets[J]. Cell, 2015, 161(5): 1202-1214. doi: 10.1016/j.cell.2015.05.002
-
[55]
KLEIN A M, MAZUTIS L, AKARTUNA I. Droplet barcoding for single-cell transcriptomics applied to embryonic stem cells[J]. Cell, 2015, 161(5): 1187-1201. doi: 10.1016/j.cell.2015.04.044
-
[56]
ZHENG G, TERRY J M, BELGRADER P. Massively parallel digital transcriptional profiling of single cells[J]. Nat Commun, 2017, 8(14049): 1-12.
-
[57]
AZIZI E, CARR A J, PLITAS G. Single cell map of diverse immune phenotypes in the breast tumor microenvironment[J]. Cell, 2018, 174(5): 1293-1308. doi: 10.1016/j.cell.2018.05.060
-
[58]
HAN X P, WANG R Y, ZHOU Y C. Mapping the mouse cell atlas by microwell-seq[J]. Cell, 2018, 22(172): 1091-1107.
-
[59]
杨子宁, 郝莎, 程涛. 单细胞转录组测序技术新进展及其在造血系统研究中的应用[J]. 中国科学: 生命科学, 2020,50,(3): 287-295. YANG Z N, HAO S, CHENG T. New Advances in single cell transcriptomic sequencing technology and its application in hematopoietic system[J]. Sci Chinese Life Sci, 2020, 50(3): 287-295.
-
[60]
HASHIMSHONY T, SENDEROVICH N, AVITAL G. CEL-Seq2:sensitive highly-multiplexed single-cell RNA-Seq[J]. Genome Biol, 2016, 17(77): 1-7.
-
[61]
FU Y S, LI C M, LU S J. Uniform and accurate single-cell sequencing based on emulsion whole-genome amplification[J]. Proc Natl Acad Sci, 2015, 112(38): 11923-11928. doi: 10.1073/pnas.1513988112
-
[62]
CHU W K, EDGE P, LEE H S. Ultraaccurate genome sequencing and haplotyping of single human cells[J]. Proc Natl Acad Sci, 2017, 114(47): 12512-12517. doi: 10.1073/pnas.1707609114
-
[63]
CHAPMAN A R, HE Z, LU S J. Single cell transcriptome amplification with MALBAC[J]. PLoS ONE, 2015, 10(3): 1-12.
-
[64]
CHEN C Y, XING D, TAN L Z. Single-cell whole-genome analyses by linear amplification via transposon insertion (LIANTI)[J]. Science, 2017, 356(6334): 189-194. doi: 10.1126/science.aak9787
-
[65]
ZAHN H, STEIF A, LAKS E. Scalable whole-genome single-cell library preparation without preamplification[J]. Nat Meth, 2017, 14(2): 167-173. doi: 10.1038/nmeth.4140
-
[66]
RAMSKOLD D, LUO S, WANG Y C. Full-length mRNA-seq from single cell levels of RNA and individual circulating tumor cells[J]. Nat Biotech, 2012, 30(8): 777-782. doi: 10.1038/nbt.2282
-
[67]
POCELLI S, BJORKLUND A K, FARIDANI O R. Smart-seq2 for sensitive full-length transcriptome profiling in single cells[J]. Nat Meth, 2013, 10(11): 1096-1098. doi: 10.1038/nmeth.2639
-
[68]
ZIEGENHAIN C, VIETH B, PAREKH S. Comparative analysis of single-cell RNA sequencing methods[J]. Mol Cell, 2017, 65(4): 631-643. doi: 10.1016/j.molcel.2017.01.023
-
[69]
阎海, 王思振, 焦宇辰, 等. 一种快速构建扩增子文库的方法: 中国107012139. A[P]. 2017-08-04.YAN H, WANG S Z, JIAO Y C, et al. A Fast method for constructing an amplicon library: CN, 107012139.A[P]. 2017-08-04.
-
[70]
DI L, SUN Y, LI J. RNA sequencing by direct tagmentation of RNA/DNA hybrids[J]. Proc Natl Acad Sci, 2020, 117(6): 2886-2893. doi: 10.1073/pnas.1919800117
-
[71]
ROSENBERG A B, ROCO C M, MUSCAT R A. Single-cell profiling of the developing mouse brain and spinal cord with split-pool barcoding[J]. Science, 2018, 360(6385): 176-182. doi: 10.1126/science.aam8999
-
[1]
-

表 1 NGS文库制备试剂盒比较
Table 1. Detailed comparison of the current NGS library preparation kits
文库制备试剂盒
Library preparation kit输入量
Input插入片段长度
Insert size处理时间
Assay time扩增
Amplification公司/货号
Company/No第二代测序
The SecondTruSeq DNA PCR-Free 1 μg 350 bp or 550 bp 5 h No Illumina
20041794Generation Sequencing TruSeq DNA Nano 100 ng 350 bp or 550 bp 6 h Yes Illumina
20015964NEBNext Ultra II FS 500 pg~1 μg 50 bp~1000 bp 3.2 h Yes New England
Biolabs #E6177Topomize DNA 500 ng 500 bp 1.5 h Yes MCLAB
TOPO-100NexteraXT DNA 1 ng~500 ng 350 bp or 550 bp 3.5 h Yes Illumina
FC-131-1024Ion AmpliSeq 10 ng 100 bp~200 bp 3.5 h Yes Thermofisher
4480441NEBNext Ultra II
RNA10 ng~1 μg 200 bp
~ 500 bp6.8 h Yes New England
Biolabs #7770TruSeq RNA 0.1 μg~1 μg 200 bp~500 bp 10.5 h Yes Illumina
RS-122-2001第三代测序
The ThirdLigation 1 μg 150 kb 1 h No Nanopore
SQK-LSK109Generation Sequencing Rapid 400 ng 150 kb 10 min No Nanopore
SQK-RBK004PCR 100 ng PCR length PCR+1 h Yes Nanopore
SQK-PSK004Direct RNA 500 ng RNA length 1.7 h No Nanopore
SQK-RNA002PCR-cDNA 1 ng ploy(A) cDNA length 2.8 h Yes Nanopore
SQK-PCS109CircAID-p-seq 4.5 pg 20 bp~50 bp 24 h No Immagina Biotech
#CA001 下载: 导出CSV
下载: 导出CSV
-









 扫一扫看文章
扫一扫看文章
计量
- PDF下载量: 297
- 文章访问数: 11872
- HTML全文浏览量: 3361
